Twój koszyk jest obecnie pusty!












Ostatnimi czasy na jednej z grup facebookowych natknąłem się na informacje o nowym systemie open-source o nazwie Kotaemon, który wzbudził moje zainteresowanie. Postanowiłem sprawdzić go w działaniu, zwłaszcza że na jego stronie na GitHubie zaprezentowano kilka interesujących funkcji. Kotaemon to otwartoźródłowe narzędzie oparte na metodzie Retrieval-Augmentation-Generation (RAG), które obiecuje możliwość interakcji z dokumentami w formie sesji pytań i odpowiedzi. Przyciągnęła mnie zwłaszcza jego elastyczność i zaawansowane funkcje, które mają pomóc w budowaniu i eksplorowaniu własnej bazy wiedzy, a także:
- Wsparcie dla lokalnych LLM i API – Narzędzie integruje się zarówno z lokalnymi modelami językowymi, jak i dostawcami API, oferując elastyczność w korzystaniu z różnych technologii sztucznej inteligencji. Wybór lokalnych modeli daje większe bezpieczeństwo danych, co jest istotnym aspektem dla firm lub osób, które muszą chronić poufne informacje.
- Hybrydowa wyszukiwarka RAG – Połączenie wyszukiwania pełnotekstowego oraz z wykorzystaniem wektorów umożliwia bardziej precyzyjne wyniki zapytań.
- Multimodalna obsługa dokumentów – Kotaemon wspiera nie tylko tekst, ale także grafy i tabele, co czyni narzędzie idealnym do pracy z różnorodnymi materiałami.
- Zaawansowane cytowania – Użytkownicy mogą korzystać z podglądu dokumentów PDF bezpośrednio w przeglądarce oraz z narzędzi do generowania dokładnych cytatów, co ułatwia pracę z dużą ilością materiału źródłowego.
- Złożone rozumowanie i podział problemów – Narzędzie wspiera bardziej skomplikowane procesy analizy i rozkładania problemów na mniejsze części, co jest kluczowe w pracy badawczej.
Dlatego postanowiłem go sprawdzić osobiście i w tym artykule podzielę się z Wami moimi wrażeniami.
Uruchomienie Kotaemon
Narzędzie może zostać uruchomione na kilka sposobów. Dla osób nietechnicznych zostały przygotowane dwa łatwe do uruchomienia scenariusze:
- uruchomienie online za pomocą HuggingFace Space
- uruchomienie lokalne za pomocą skryptu
run_windows.batlubrun_macos.shlubrun_linux.sh
Ja wybrałem instalację za pomocą Docker’a. System Kotaemon korzysta z biblioteki unstructured.
Unstructured.io to narzędzie służące do przetwarzania i analizowania nieustrukturyzowanych danych. Narzędzie to specjalizuje się w konwersji różnych formatów danych (np. PDF, obrazy, e-maile, dokumenty tekstowe) na bardziej uporządkowane i strukturyzowane informacje, które można następnie łatwiej przetwarzać i analizować za pomocą algorytmów sztucznej inteligencji, takich jak modele językowe (LLM). Jest to wymagająca biblioteka ze względu na różnorodność formatów danych, które obsługuje. Dlatego zostały przygotowane 2 wersje kontenerów Docker: lite oraz full. Wersja full instaluje więcej paczek do obsługi formatów, przez co obraz zajmuje więcej miejsca. Ja zainstalowałem tą właśnie wersję, chociaż podobno wersja lite jest wystarczająca dla większości przypadków.
Uruchomienie obrazu Dockera przebiega za pomocą komendy:
docker run \
-e GRADIO_SERVER_NAME=0.0.0.0 \
-e GRADIO_SERVER_PORT=7860 \
-p 7860:7860 -it --rm \
--platform linux/arm64 \
ghcr.io/cinnamon/kotaemon:main-litePo uruchomieniu system Kotaemon jest dostępny pod adresem lokalnym http://localhost:7860.
Pierwsza konfiguracja Kotaemon
Po wejściu na adres lokalny musimy skonfigurować narzędzie.
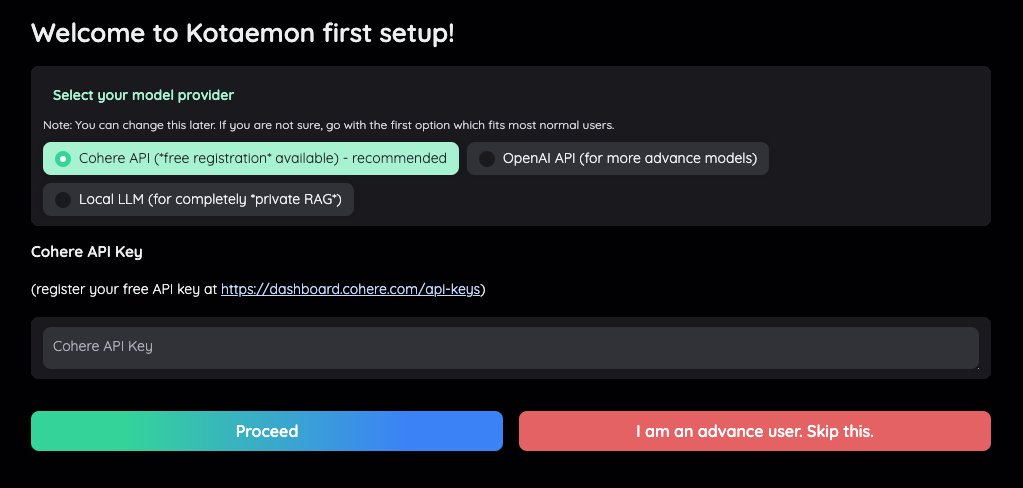
W pierwszym kroku musimy wybrać model LLM, który będzie nas obsługiwał. Sugerowanym domyślnie API jest Cohere.
Cohere to platforma oferująca zaawansowane modele językowe, które umożliwiają tworzenie aplikacji opartych na sztucznej inteligencji, takich jak generowanie tekstu, analiza sentymentu czy klasyfikacja danych. Cohere kładzie duży nacisk na personalizację modeli i prywatność danych, co czyni ją atrakcyjnym wyborem dla firm dbających o bezpieczeństwo informacji.
W tym teście sprawdzę działanie Kotaemon właśnie z modelami z Cohere. Musimy wygenerować klucz API, co wymaga założenia konta w Cohere.
Po dodaniu klucza API w Kotaemon, w kolejnym kroku należy utworzyć pierwsze konto użytkownika.
Po utworzeniu konta mamy już dostęp do interfejsu panelu. Mogę więc już podsumować, że instalacja i pierwsza konfiguracja przebiegła bardzo szybko i sprawnie.
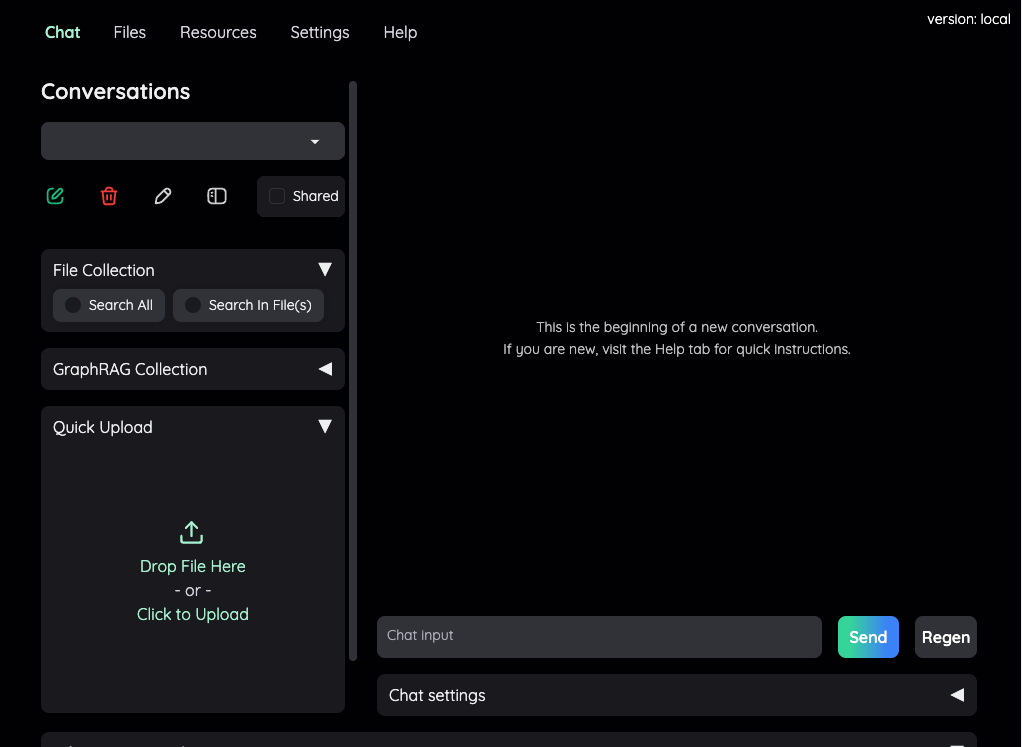
Pierwszy plik, pierwsze zapytanie…
W panelu z lewej strony znajduje się panel „Quick Upload”, w którym wgrywam pierwszy plik PDF, a następnie w polu czatu zadaję pytanie: „Ile rozdziałów zawiera ten plik?”
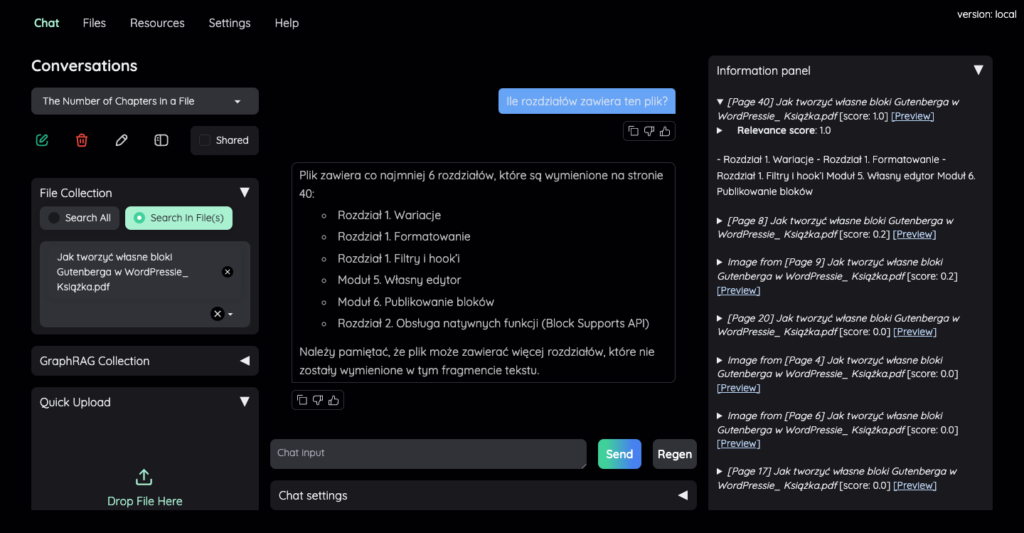
Odpowiedź na tak zadane pytanie nie jest poprawna. Jest to pewna wada rozwiązań typu RAG, które zawężają kontekst LLM do skrawków zaindeksowanych treści. Co jednak ciekawe w narzędziu Kotaemon, po zadaniu pytania w panelu z prawej strony znajdują się odniesienia skrawków wraz z ich „relevance score” czyli współczynnikiem dopasowana. W niektórych pozycjach możemy nawet kliknąć link „Preview”, który otworzy dokument PDF w wyznaczonym miejscu. Dzięki temu możemy dokładnie zobaczyć co wziął pod uwagę model, generując odpowiedź na pytanie.
Drugi plik….
Tym razem wgrałem plik PDF, który zawierał większą liczbę stron, a także dane tabelaryczne i wykresy. Indeksacja pliku trwała krótko. Przy zadawaniu pierwszego pytania okazały się problemy. Wyglądało jakby chat się zawiesił, a po zajrzeniu do konsoli, widać było powtarzające się błędy, które uniemożliwiły dalszą eksplorację.

Wstępne podsumowanie
Narzędzie Kotaemon to ciekawa inicjatywa open-source, która ma na celu stworzenie interfejsu do obsługi architektury RAG. Repozytorium projektu w ciągu ostatniego miesiąca otrzymało ponad 12k gwiazdek na github’ie i otrzymało tytuł „Repository of the Day”. Jest to na pewno projekt wart uwagi i na pewno będę do niego wracał w kolejnych artykułach, aby dokładnie poznać jako mocne i słabe strony.